Patterns and selections
Because so much of the web is templated and generated from data stored in databases, it's also predictable in its structure.
For example, take WordPress, the popular blogging content management system. At its most basic, it's designed to take data for blog posts stored in a database and display them. It does this by running a "loop" over all the posts to be displayed.
That loop looks like this:
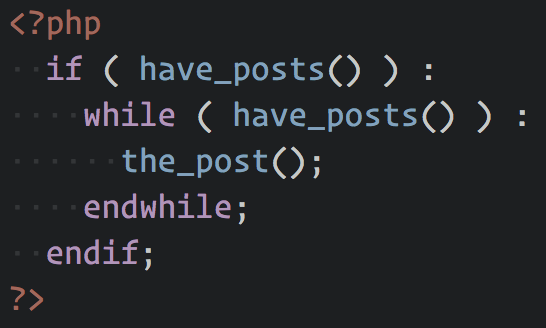
So each post will have, for the most part, exactly the same HTML structure.
Before we dive into that structure, let's start with something a bit more basic: text itself.
Just as HTML has a structure, so does text itself (thanks, linguistics!). Namely, you have characters, digits, spaces, word boundaries, etc.
A long time ago, someone figured out we could create a sort of "language" (it's not really a language) to search and query text using these formal characteristics. That's what we call regular expressions, or regex for short.
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.
It is often hard to write and difficult to read, so many people hate it. But it's powerful.
Here's an example of a regular expression (please bear with me!):
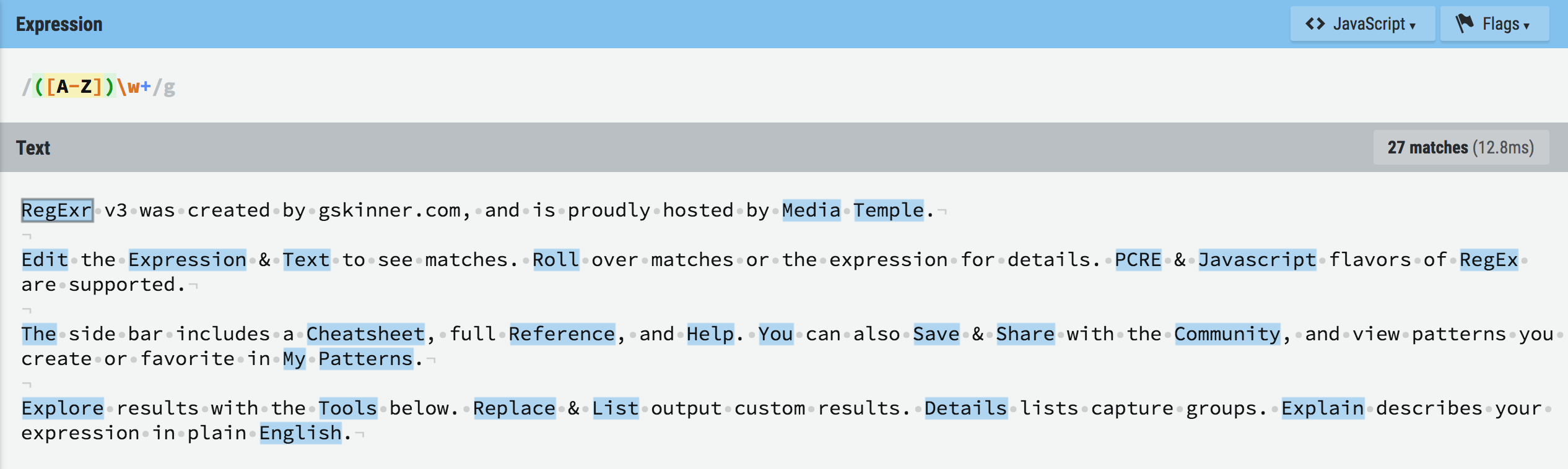
Let's write a few of our own together.
Next up: selecting DOM nodes!
In the same way that we can use regex as a set of instructions to select text, we can use a certain sequence of text to select elements in the DOM.
There are two common ways of doing this: selectors and XPath.
Selectors are far and away the most common, because they're a bit easier to read and are used in JavaScript.
XPath looks a lot more like regex, and can be annoying to get right.
Both are useful, and luckily for us nowadays browsers can do a lot of the work in telling us what our selection text will be.
Let's use Dev Tools to look at some markup on The Globe and Mail's homepage and see if we notice some patterns.
Now that we've noticed a few, let's try and grab text for all the headlines on The Globe's homepage.
let data = document
.querySelectorAll('.o-card__hed-text')
.forEach(d => d.textContent);
console.log(data);
With those four lines of code, we've just written our first scraper.
Exercise time: let's all pick a website, identify the structure and write a basic document.querySelectorAll query together to grab some nodes.
Lunch time!
Previous section: Part 2: The basics of markup
Next section: Part 4: Writing your first scraper with rvest