The basics of markup
Webpages, how do they work?

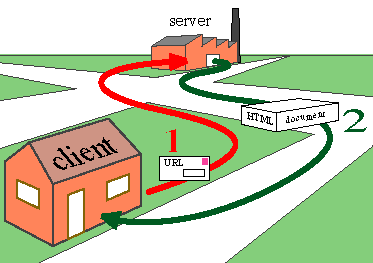
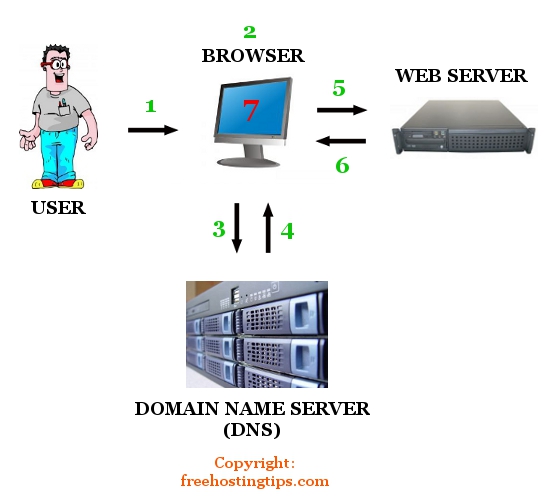

Three parts
1. A server, which hosts files and data, and is often an application unto itself that can generate pages on-the-fly
2. A browser, or "client," which connects to a server and requests stuff
3. The gluey part in the middle (domain names, load balancers, templating engines)
Scraping is primarily concerned with extracting data from what we call the "front end", or the stuff that gets rendered in your browser (servers are often called the "back end").
You can extract data directly from a server, but often that's done through hacking, which is bad.
The difference is that with scraping, you're selecting information that's been made public by the person or organization running the web page. The information's all there!
So, how do web pages work?
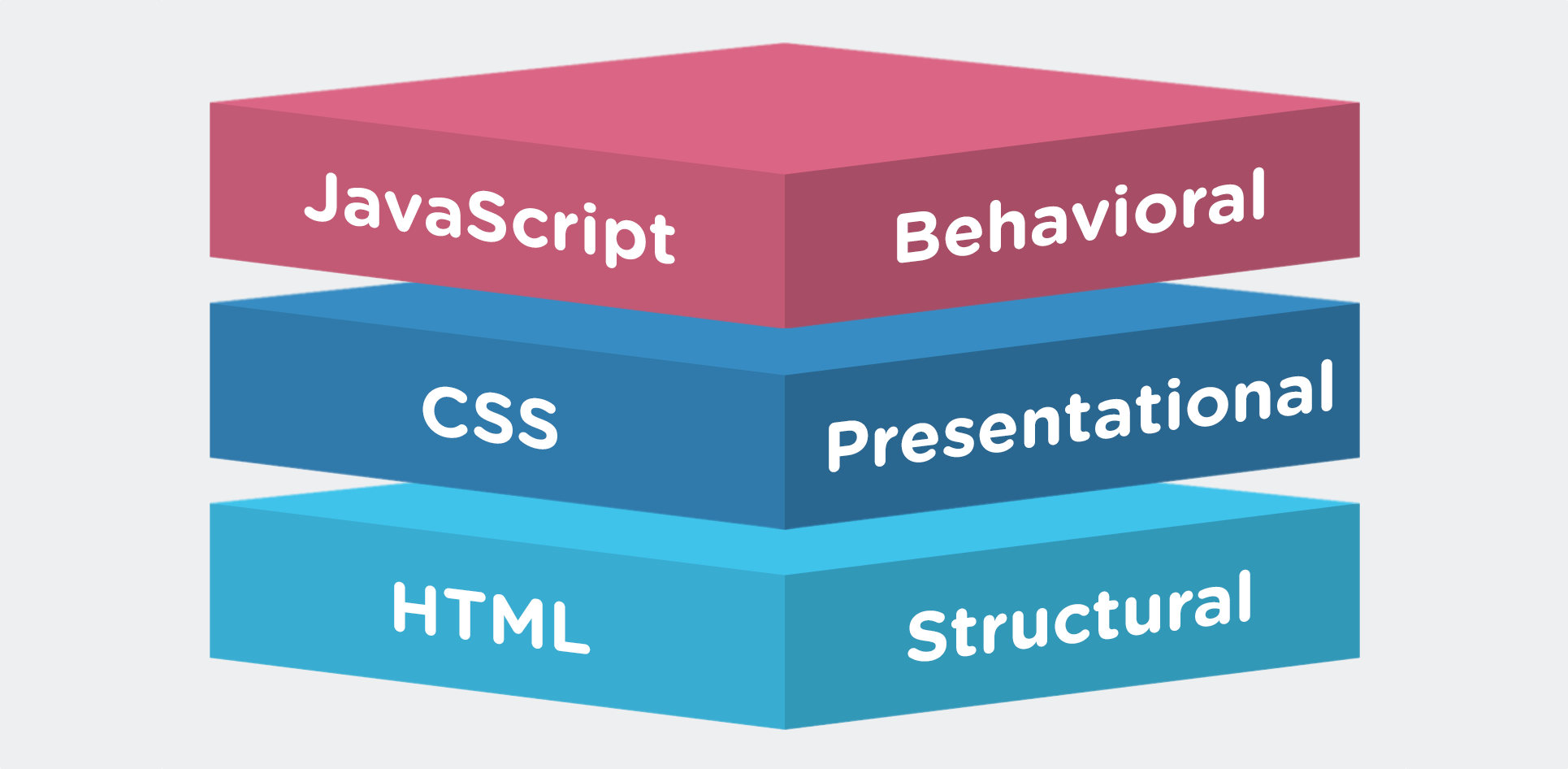
If web pages were an IKEA dresser…
HTML would be the assembly instructions
CSS would be the tchotchkes you use to decorate it
JavaScript is the functionality, allowing you to open and close your drawers (most of the time, anyway — this is IKEA after all…)
In almost all cases, scraping is concerned primarily with HTML.
We don't care how it looks or what happens when you click a button. We just want the data!
The way we access this information is through a concept called the DOM.
Stands for document object model. It's a standard maintained by the World Wide Web Consortium.
The DOM is the common structure of all web pages, and is what allows browsers to know how to parse the data they receive from the server. In the IKEA example, it would be the fact that all assembly instructions are printed on paper using ink and language that we know how to read.
At its core, the DOM (and HTML) follows a tree model. The top-level node is the html element, and everything else is a child of that element.
Enough talking — let's check it out for ourselves! Go to a web page, right-click anywhere and click on "view source."
The web is more than just HTML, CSS, JavaScript, though. There's also APIs, or application programming interfaces.
These days, APIs power a lot of the web. Your smart phone uses APIs to get weather data, check your email, send you map directions when you're lost on Wilfrid Laurier's campus on your way to teach this class…
APIs are a machine-readable data interface (unlike HTML, which is still machine-readable but designed for normal human consumption). You write code requesting a certain chunk of data, and the server knows how to parse that and returns you data in a structured way.
API data usually manifests in two "flavours:"
JSON (pronounced like "Jason"), or "JavaScript object notation" (no one calls it that)
XML, which has fallen out of favour in the last decade because it's annoying to parse and debug
fetch('https://jsonplaceholder.typicode.com/posts/1')
.then(response => response.json())
.then(json => console.log(json))
Let's fire up Chrome Developer Tools and find out what that code does.
Right click anywhere on any webpage and click on "inspect."
Exercise: Let's get familiar with Dev Tools
15 minute break!

Previous section: Part 1: Introduction
Next section: Part 3: Patterns and selections